: Designing an Artificial Language: Phonology Author: Rick Morneau MS Date: 12-06-1998 FL Date: 11-01-2018 FL Number: FL-000056-00 Citation: Morneau, Rick. 1998. «Designing an Artificial Language: Phonology.» FL-000056-00, Fiat Lingua,
Phonology
by Rick Morneau
September, 1991
[Minor changes made on July 20, 1994 and December 6, 1998]
Copyright © 1991, 1994, 1998 by Richard A. Morneau,
all rights reserved.
[The following essay was published in the September 1991
issue of the Linguica APA (Issue #9). I have made a few
minor changes since then.]
Introduction
In designing the phonology of your artificial language (henceforth AL), you have several
choices:
1. Choose phonemes that you are most familiar with.
2. Choose phonemes that appeal to you aesthetically.
3. Choose phonemes to maximize your phonemic inventory.
4. Choose phonemes that most people in the world already
know or can learn to pronounce easily.
5. Choose phonemes based on morphological, syntactic,
semantic or other requirements.
Number 1 appears to be the choice in all self-claimed universal ALs. ALs that fall into this
category are Esperanto, Glossa, Loglan/Lojban, Ido, Intal and many others. In all of these, the
designers started with the sounds they were familiar with, eliminated one or two that they
thought were not very common, and sometimes added one or two others to flesh things out.
Number 2 is the choice of people who design ALs just for the fun of it, or for personal use.
People in this category are not likely to find this essay very interesting. 🙁
Number 3 was the choice of the characters who designed the super language in Robert A.
Heinlein’s short story, Gulf. Aside from Heinlein’s story, and to the best of my knowledge, no AL
has ever been designed with a maximal phonemic inventory.
As for number 4, to my knowledge, no serious AL has ever been designed to make pronunciation
as easy as possible for as many people as possible (contradictory claims notwithstanding). I
1
believe that this is the case simply because most AL designers have very little knowledge of the
phonologies of natural languages other than their own.
Number 5 covers any requirement that is not covered by numbers 1-4. In effect, it is a none-of-
the-above choice. I’ll have more to say on this one later.
For obvious reasons, there’s not much more that I can say about numbers 1 and 2, since they are
based on what is essentially personal preference. However, a lot more can be said about the
remaining choices, which I will attempt to do later. First, though, I think it would be a good idea
to look at what’s available to us; that is, how large is the set of possible phonemes that we can
choose from to create the phonemic inventory of an AL?
The Phoneme Chart
In the accompanying chart (Postscript or PNG) I have compiled the phonemic values present in
twenty-five of the world’s major languages. Give it a good looking over before reading on – the
chart is deceptively simple, as I will explain in subsequent paragraphs.
2
[For those of you who are not using a browser that can display a PNG file, follow this link for a
verbal description of the chart.]
The information in the chart was obtained from several sources. However, the most important
source was «The World’s Major Languages» edited by Bernard Comrie. (Incidentally, if I had
known in advance how much time and effort would go into the making of this chart, I never
would have started it. From hindsight, though, I think it was worth it. I hope you agree.)
Before wading into the thick of things, first let me explain what’s wrong with the chart. When I
first started putting it together, I had planned to include all of the phonemes for the listed
languages. As I proceeded, however, I realized that to do so would require a VERY BIG CHART,
much bigger than I could fit on a single page. So, as any other normal, sane, intelligent and good-
looking person would do, I compromised. Basically, what I did was eliminate phonemic feature
distinctions that were made by only a small minority of languages. Aspiration went first, then
nasalization, then labialization, etc. The whole gory excision is explained in the footnote at the
bottom of the chart. Even so, I was not entirely consistent, as any astute observer will surely
notice (for example, /palatalized-n/ and /palatalized-l/ survived). To add insult to injury, I
combined some phonemes that were articulated in slightly different positions and/or which
sounded so similar that most people would not be able to tell them apart (boxes labelled «X or Y»
fall into this category). Some of the vowel allocations may raise a few eyebrows (and perhaps a
few hackles), but then who ever agrees about vowels? Finally, you’ll note that most of the IPA
symbols used do not reflect the latest version of the IPA standard. The reason is that my brain-
damaged IPA font was missing a few of the newer symbols but has all of the older ones, and I
decided to be consistent. Besides, almost all of my sources used the older symbols, and I suspect
that most linguists continue to use the older symbols out of habit. Fortunately, only a few have
been changed, and there is no chance of confusion.
Next, let me explain some things that are not so embarrassing. Chinese (Man) means Mandarin
Chinese, Portuguese (Eu) means European Portuguese (as opposed to Brazilian or African
dialects of Portuguese), Spanish (Cas) means Castilian Spanish, and Vietnamese (S) means
South Vietnamese. For the last three consonants, the plus sign «+» indicates co-articulation.
In spite of the fact that professional phonologists may shudder at the result, I do feel that the
chart is adequate for use in designing an artificial language.
The next step is to decide how to use the chart. This really depends on whether you are trying to
design an AL that is maximally concise, maximally pronounceable or maximally «something-
else».
Designing a Maximally Concise AL
If you wish your AL to be as concise as possible, then you’ll want to maximize your phonemic
inventory; that is, you’ll want your language to have as many phonemes as possible. Consider,
for example, an AL with a morpheme (root word) structure of CVC, where C is a consonant and
V is a vowel. If you are working with the phonemic inventory of Japanese, then you’d have about
3
5 vowels and 14 consonants. Thus, the number of possible monosyllabic morphemes would be
14x5x14 = 980. If you are working with the phonemic inventory of English, then you’d have
about 15 vowels and 24 consonants (depending on dialect and on who’s counting). Thus the
number of possible monosyllabic morphemes would be 24x15x24 = 8,640. If we made an
aspirated/unaspirated phonemic distinction among the stops (as Hindi does), and if we added
glottalized emphasis to several other consonants (as in Arabic), we could add 6+6 = 12 new
consonants for a total of 24+12 = 36 consonants. Thus, the number of possible monosyllabic
morphemes would grow to 36x15x36 = 19,440. By continuing this process, many more
consonants could be added to increase the number even further. The result would be difficult to
pronounce for most people, but it could be learned with practice.
Obviously, the objective here is to have as many phonemes as possible. Since I would never want
to actually learn a language like this, I’m not going to create what I would consider an optimal
maximum phonemic inventory – I’ll leave that up to someone who is more biased in favor of this
whole approach. Instead, I’ll just mention a few things that may be of interest to such a designer.
There are two general ways of increasing the number of vowels: nasalization and tones.
Nasalization is either on or off, and can only double the number of vowels. Tones, however, can
multiply the number of vowels by the number of tones. Thus, if you have four ones, then you’ll
have four times as many vowels. If you do choose to use tones, keep them short. For example, if
you decide to base your tonal system on Mandarin Chinese (which has four tones), make sure to
shorten the low tone, since it almost doubles the length of the syllable. You can increase the
number of tones to six (as in Vietnamese) or seven (as in Cantonese), but your language will
become quite difficult to master.
As for consonants, you’ll probably want to start with most of the unmarked phonemes in the
chart. Next, you might try making phonemic distinctions using aspiration and velarization (also
called emphasis or glottalization) as I mentioned above. I do not think that palatalization will be
productive if you also have the phoneme /j/. (Although /palatalized-n/ is not the same as /nj/,
they are too close for comfort. At any rate, I would not bother with palatalizing any consonants. I
would make free use of /j/ instead.) Labialization and /w/ can be handled similarly. Some
languages implode voiced stops but do not, to my knowledge, use implosion to make phonemic
distinctions – give it a try! Ditto for retroflexing. You might even want to create some new co-
articulated consonants. Gemination doesn’t really gain you anything (this also applies to vowels),
since you’re doubling the length of the phoneme. Finally, you may want to consider the various
clicks and pops used in some south African languages, although I did not list them in the chart.
Whatever you end up with, please don’t try to teach it to me. 🙂
With polysyllabic morphemes, you can increase your mileage by making distinctions based on
stress. For example, the meaning of the English word «present» depends on whether the stress is
on the first syllable (=a gift) or on the second syllable (=to introduce). Orthographically, stress
can be indicated with a diacritic (i.e., accent mark), capitalization, or by some other means. For
example, «SIMba» could mean «cheese», while «simBA» could mean «river».
4
Designing a Maximally Pronounceable AL
Most AL designers choose phonemes that they are familiar with. Unfortunately, they do so not
realizing how difficult some of their choices may be for people of different linguistic
backgrounds. So, the goal here is to select a phonemic inventory that is easy to pronounce or
easy to learn for everyone. The tough part is deciding what the word «easy» means. In the
following paragraphs, I will discuss a few approaches to the design of a phoneme inventory that
is «easy» for as many of the world’s inhabitants as possible.
Brief Digression on Phonetic Notation
Letters written between slashes represent phonemes (minimal
units of sound). However, it is possible for a phoneme to
have more than one pronunciation. For example, the
phoneme /s/ in the English words cats and dogs is
pronounced like «s» in cats but like «z» in dogs. This
sound difference is indicated by enclosing the actual sound
between square brackets. Thus, for example, the /s/
in cats is pronounced [s], while the /s/ in dogs is
pronounced [z]. Phonemes with alternate pronunciations are
called allophones.
1. Easy for all – choose only those phonemes that appear in all 25 languages. Using this
approach we can start with the following phonemes: /t/, /k/, /s/, /m/ and /u/, which appear in all
25 languages. Next, we can combine /i/ and /I/ into the single phoneme /i/, since they are very
close. Similarly, /A/ and /a/ can be combined into /a/. The net result is 7 phonemes: /t/, /k/, /s/, /
m/, /a/, /i/ and /u/. Thus, the number of morphemes with the form CVC will be 4x3x4 = 48. In a
language with this phonemic inventory, words are likely to be quite long. However, as long as
you don’t use consonant clusters, your language will be extremely easy to pronounce no matter
what a learner’s native language is.
A possible extension to this approach would be to allow more than one pronunciation for a single
phoneme, even if they are not similar. For example, you could use /r/ to represent the sounds [l],
[r], [R], plus all the other rhotics. In other words, make them legal allophonic variants for /r/.
Also, how about using /h/ to represent both [f] and [h]? Japanese does something very similar – /
h/ represents the allophones [unvoiced bilabial fricative] and [h]. Finally, you can reduce the
number of languages in the list from 25 to a smaller number, by eliminating those languages that
you consider unimportant. For example, by eliminating Yoruba, you get /n/. By eliminating
Japanese, you get /l/. And so forth. This process can also be used in the remaining «easy»
approaches discussed below, and I will say no more about it.
2. Share the pain – start with «super easy» and add phonemes in a way that causes the learning
burden to be shared equally. In other words, make it a requirement that no speakers will have to
learn more than N new phonemes, where N is very small (1, 2 or 3). I played around with this for
a while and came to the conclusion that you can add at least N and perhaps N+1 new consonants
5
to the «super easy» inventory. If you look at all possibilities, this could be a time-consuming
process, more suited to a computer. As far as I’m concerned, the gain is not worth the pain.
3. Majority wins – choose phonemes that appear in X% of the 25 languages. In other words, all
we are doing here is drawing a line: people on one side of the line will already know all the
phonemes, while people on the other side will have to learn one or more new ones. Note that if X
= 100%, then this is equivalent to the «super easy» case. Here’s a list of what you get as the
percentage gets smaller and smaller (please note that I’m using /sh/ for English «sh» in «ship»,
and /ch/ for English «ch» in «chip»):
Percentage Consonants Vowels
===========================================================
100% t k s m u
96% t k s l j m n i u a
92% t d k s l j m n i u o a
88% p b t d k s l j m n i u e o a
84% p b t d k f s l j m n no change
80% no change no change
76% p b t d k g f s l j m n no change
72% p b t d k g f s sh l j m n r no change
68% p b t d k g f s z sh h ch l j m n r no change
64% p b t d k g f v s z sh h ch l j m n r no change
And so forth. Keep in mind that /r/ is an alveolar flap or trill – it is not like the English or
Chinese retroflexes, which are quite different. However, if you let /r/ represent any of the rhotics
[r], [R], etc., then it will move to the 96% line. In the same vein, if you let /h/ represent [h] or [x],
then it will move to the 88% line.
Choosing Phonemes Based on Other Requirements
In this case, your requirements will determine or limit your choices. For example, if the
morphology of your AL requires a voiced/unvoiced symmetry in your fricatives, then choose one
of the above approaches and fill in the gaps. Thus, if you choose the 76% line in the above table,
you could add /v/ and /z/ to create the symmetry you need. As it turns out, this may not really
make the language more difficult to learn. Once a speaker knows how to make a voiced/unvoiced
distinction, such as /s/ vs. /z/, it is usually easy to learn new ones. In other words, if you already
know /s/, /z/ and /f/, you can master /v/ with almost no effort at all.
As another example, if the semantics of your AL requires a three-way distinction and you don’t
want to add a syllable or create a difficult-to-pronounce consonant cluster, you could use the
semivowels /j/ and /w/. Thus, you could make three-way distinctions such as /ka/, /kja/ and /
kwa/.
6
And so on. Obviously, in situations like the above, you will have decided that some requirements
are more important than others. Thus, in both of the above examples, ease of pronunciation was
less important than other requirements.
End of Essay
7![]() . Web. 01 November 2018. Copyright: © 1998 Rick Morneau. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. http://creativecommons.org/licenses/by-nc-nd/3.0/ Designing an Artificial Language: image» />
. Web. 01 November 2018. Copyright: © 1998 Rick Morneau. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. http://creativecommons.org/licenses/by-nc-nd/3.0/ Designing an Artificial Language: image» />![]() . Web. 01 November 2018. Copyright: © 1998 Rick Morneau. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. http://creativecommons.org/licenses/by-nc-nd/3.0/ Designing an Artificial Language: image» />
. Web. 01 November 2018. Copyright: © 1998 Rick Morneau. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. http://creativecommons.org/licenses/by-nc-nd/3.0/ Designing an Artificial Language: image» />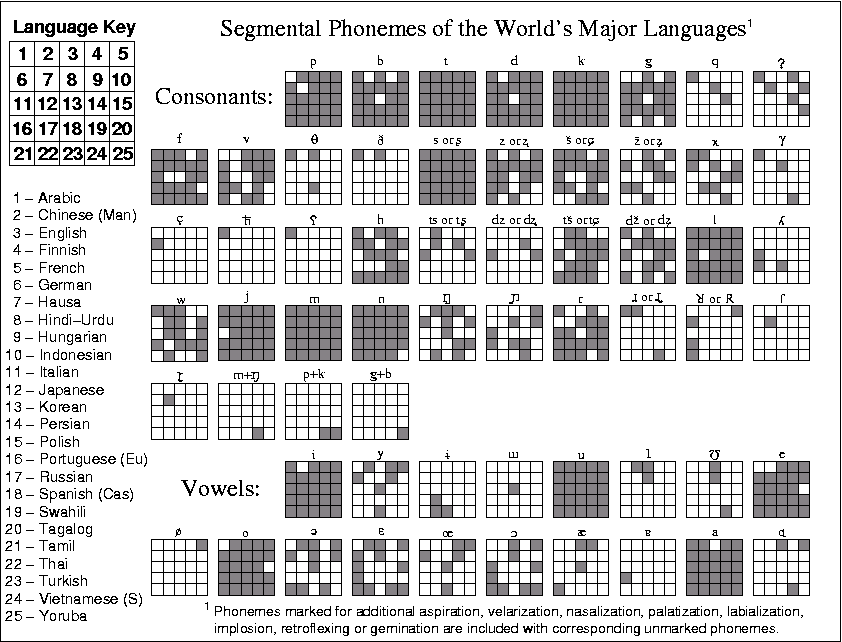 . Web. 01 November 2018. Copyright: © 1998 Rick Morneau. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. http://creativecommons.org/licenses/by-nc-nd/3.0/ Designing an Artificial Language: image» />
. Web. 01 November 2018. Copyright: © 1998 Rick Morneau. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License. http://creativecommons.org/licenses/by-nc-nd/3.0/ Designing an Artificial Language: image» />
